Fig 1. Simple expression
Static code analyzer for Python
Table of Contents:
Download:
http://www.unixuser.org/~euske/python/pyntch/pyntch-20091028.tar.gz
(50KBytes)
Discussion: (for questions and comments, post here)
http://groups.google.com/group/pyntch-users/
View the source:
http://code.google.com/p/pyntch/source/browse/trunk/pyntch
Pyntch (pron. "pinch", originally means PYthoN Type CHecker) is a static code analyzer for Python programming language. It detects possible runtime errors before actually running a code. If you have been constantly bothered by a TypeError or AttributeError caused by giving a wrong type of objects, Pyntch is a tool for you. Pyntch examines a source code and infers all possible types of variables, attributes, function arguments, and return values of each function or method (take a look at a sample output below). Then it detects possible exceptions caused by type mismatch, attribute not found, or other types of exceptions raised from each function. Unlike other Python code checkers (such as Pychecker or Pyflakes), Pyntch does not address style issues. Pyntch normally runs pretty fast. It can perform checking for tens of thousands of lines of code within a minute.
Note: Pyntch currently supports Python 2.x only.
The following information can be gathered by static checking:
obj.attr where obj does not have attribute attr).
a[1] where a is not a sequence).
func(1) where func is not either function, method, or class).
sorted(x) where x is not an iterable object).
(Original code)
import sys, os
# Count the total number of characters for each file in directory.
def countchars(directory):
n = 0
for name in os.listdir(directory):
fp = open(name)
for line in fp:
n += line
fp.fclose()
return n
countchars(sys.argv[1])
(Annotated by Pyntch)
# os = <module os> # sys = <module sys> import sys, os # Count the total number of characters for each file in directory. def countchars(directory): # directory = <str> # fp = <file> # line = <str> # n = <int> # name = <str> # return <int> n = 0 for name in os.listdir(directory): fp = open(name) for line in fp: # raise TypeError: not supported operand Add(int, str) n += line # raise AttributeError: attribute not found: @fp.fclose # raise AttributeError: attribute not found: <file>.fclose fp.fclose() return n countchars(sys.argv[1])
Have you had a TypeError caused by giving a wrong type of arguments, say, a string object to numeric functions? Or trying to access a nonexistent method of a wrongly passed class that would otherwise have such a method? One of the great advantages of scripting languages such as Python is its dynamicity. You can define any functions, variables and data structures whenever you want without elaborating the detailed type definitions. However, this feature comes with some cost: sometimes it is difficult to find potential errors that are caused by type mismatch before actually running the program.
In a language like Python, there is always a risk of uncaught runtime exceptions that a programmer could not foresee when s/he was writing the code, which causes sudden death of the program. This kind of behavior is particulary unfavorable for mission critical applications, so we want to catch these errors in advance. Unfortunately, as the program gets larger, it's getting hard to track these kinds of errors, and it's even harder to prevent them by infering which types/values can be passed or returned by each function.
Pyntch aims to help reducing these burdens by infering what kind of types can be assigned to variables/members/function arguments and what kind of types can be returned from a function at any time of execution, and what kind of exceptions might be raised. This is done by examining the code without executing it. The goal of Pyntch is to try to analyze every possible execution path and all possible combinations of data.
Sounds impossible? Well, I can show you at least this is partially possible, by using a technique called "typeflow analysis." For the details, see How it works? section. However, there's also a couple of drawbacks. Because the purpose of Pyntch is to catch as many obscure errors as possible before the code is acutally used in a production, it focuses on the coverage of the analysis at the expense of its accuracy. Sometimes Pyntch brings a lot of false positives in its result, which need to be further examined by human programmers.
setup.py to install:# python setup.py install
The main checking program is tchecker.py.
It comes in two different running modes:
summary mode and annotation mode.
In summary mode, Pyntch only shows the types of each variable and exceptions in a succinct text format. In annotation mode, there're two stages. First, the analyzer program produces an XML file that contains all information about a source code. Then another program uses that information to annotate the source texts.
The basic use of summary mode is pretty simple and straightforward. Take this sample code:
$ cat -n sample.py
1 import sys, os
2
3 # Count the total number of characters for each file in directory.
4 def countchars(directory):
5 n = 0
6 for name in os.listdir(directory):
7 fp = open(name)
8 for line in fp:
9 n += line
10 fp.fclose()
11 return n
12
13 countchars(sys.argv[1])
To check this code, simply run the tchecker.py against the source file:
$ tchecker.py sample.py loading: 'sample.py' as 'sample' ... total files=9, lines=1435 in 0.38sec .........................................[A] [sample (sample.py)] os = <Module os (/home/euske/work/pyntch/pyntch/stub/os.pyi)> sys = <Module sys (/home/euske/work/pyntch/pyntch/stub/sys.pyi)> ### sample(4) ..............................................................[B] # called at sample(13) .....................................................[C] def countchars(directory=<str>): ...........................................[D] fp = <file> ..............................................................[D] line = <str> .............................................................[D] n = <int> ................................................................[D] name = <str> .............................................................[D] return = <int> ...........................................................[E] raises TypeError: not supported operand Add(int, str) at sample:9 ........[F] raises AttributeError: attribute not found: @fp.fclose at sample:10 ......[G] raises AttributeError: attribute not found: <file>.fclose at sample:10 ...[H]
The output shows several things:
countchars starts from line 4 in sample1.py.
TypeError exception at line 10
by attempting to add an integer and string.
fp.fclose fails for any type of objects that
fp could have contained.
fclose attribute. (It should have been close instead.)
In annotation mode, first you need to run the analyzer program to
produce the result in an XML format. Then give the XML file to
another program called annot.py. This program inserts
the analysis results into appropriate places in the source code,
producing an annotated source text.
Step 1:
Now$ tchecker -o output.xml sample.py loading: 'sample.py' as 'sample' ... total files=9, lines=1435 in 0.40sec
output.xml looks like this:
<output>
<module src="sample.py" name="sample">
<var name="os"><compound id="0"><module name="os" /></compound></var>
<var name="sys"><compound id="0"><module name="sys" /></compound></var>
<function loc="sample:4:5" name="countchars">
<caller loc="sample:13" />
<arg name="directory"><compound id="0"><str /></compound></arg>
<var name="fp"><compound id="0"><file /></compound></var>
<var name="line"><compound id="0"><str /></compound></var>
<var name="n"><compound id="0"><int /></compound></var>
<var name="name"><compound id="0"><str /></compound></var>
<return><compound id="0"><int /></compound></return>
<raise msg="TypeError: not supported operand Add(int, str)" loc="sample:9" type="TypeError" />
<raise msg="AttributeError: attribute not found: @fp.fclose" loc="sample:10" type="AttributeError" />
<raise msg="AttributeError: attribute not found: <file>.fclose" loc="sample:10" type="AttributeError" />
</function>
</module>
</output>
Step 2:
$ annot.py output.xml sample.py
# os = <module os>
# sys = <module sys>
import sys, os
# Count the total number of characters for each file in directory.
def countchars(directory):
# directory = <str>
# fp = <file>
# line = <str>
# n = <int>
# name = <str>
# return <int>
n = 0
for name in os.listdir(directory):
fp = open(name)
for line in fp:
# raise TypeError: not supported operand Add(int, str)
n += line
# raise AttributeError: attribute not found: @fp.fclose
# raise AttributeError: attribute not found: <file>.fclose
fp.fclose()
return n
countchars(sys.argv[1])
tchecker.py is the main checking tool.
It scans Python source codes and shows the result of analysis.
The output can be later used for annotation purposes.
tchecker.py [options] file.py ...
-a
-c config_file
ErrorConfig settings.
-C key=value
-d
-D
-f type
txt (summary mode) or
xml (annotation mode) is supported.
-o filename
-p >python_path
-p options are allowed.
-P stub_path
-P options are allowed.
-q
annot.py is an annotation tool.
It takes an XML output of tchecker.py and combines it
with the source codes to produce annotated output.
A source file can be specified either by an actual pathname or
by a Python module name (as used with a "import" statement).
When a pathname is used, the pathname string must be exactly the one
contained in the "src" attribute in an XML output.
annot.py [options] output_xml file.py ...
or
annot.py [options] output_xml module_name ...
-p basepath
-d
Pyntch can take module names instead of actual file names as input.
Pyntch searches the Python search path that is specified by PYTHONPATH
environment variable, as well as stub path (explained below). If you want to instruct
Pyntch to look at different locations, use -p option to alter
the module search path:
$ tchecker.py -p /path/to/your/modules mypackage.mymodule
Due to the nature of source level analysis, Pyntch cannot analyze a program that uses external modules, in which the behavior of the code is specified only in opaque binaries. In that case, a user can instruct Pyntch to use an alternative "stub" module which is written in Python and defines only the return type of each function. Python stub modules are similar to C headers, but a Python stub is a real Python code that basically does nothing than returning a particular type of objects that the "real" function would return. For example, if a Python function returns an integer and a string (depending on its input), its stub function looks like this:
Although this looks meaningless, it is a valid Python code, and since Pyntch ignores its execution order (see Limitations section), Pyntch recognizes this function as one returning an integer and/or a string.def f(x): return 0 return ''
Python stub files end with ".pyi" in their file names.
They are usually placed in the default Python search path.
When a Python stub and its real Python module both exist, the stub module is checked.
Stub modules for several built-in modules such as sys or
os.path are included in the current Pyntch distribution.
They are normally placed in the Pyntch package directory
(e.g. /usr/local/lib/python2.5/site-packages) and
used by default instead of built-in Python modules.
Pyntch cannot correctly analyze a built-in function that returns
different types of values depending on its parameters
(notably struct.unpack).
It is possible to inform Pyntch that a certain variable can only have
a specific type. These constraints can be embedded in a source code
using Python's assert statement, as in:
$ cat -n assert1.py
1 def f(x):
2 assert isinstance(x, (float,int))
3 return x*2
4
5 f(1)
6 f(2.3)
7 f('foo')
$ tchecker.py assert1.py
[assert1 (assert1.py)]
### assert1(1)
# called at assert1(5)
# called at assert1(7)
# called at assert1(6)
def f(x=<float>|<int>):
return = <float>|<int>
raises TypeError: @x (<str>) must be int|float at assert1:2
Since Pyntch can produce a lot of information about a code, a user might be overwhelmed by the amount or complexity of its result. Pyntch offers a couple of ways for controlling the outputs in order to provide the desired information.
These are defined in ErrorConfig class (config.py).
raise_uncertain (boolean)
ignore_none (boolean)
show_all_exceptions (boolean)
One of the major drawbacks of typeflow analysis is its inability to take account of execution order (which is also true for dataflow analysis). The sequence of statements is simply ignored and all the possible order is considered. This is like considering every permutation of statements in a program and combining them into one. This sometimes brings inaccuracy to its result in exchange for a comprehensiveness of the checking. For example, consider the following two consecutive statements:
x = 1 x = 'a'
After executing these two statements, it is clear that variable x has always a string object, not an integer object. However, due to the lack of awareness of execution order, Pyntch reports this variable might have two possible types: an integer and string. Although we expect this kind of errors does not affect much to the overall usefulness of the report, we provide a way to supress this type of output. Also, Pyntch cannot detect UnboundLocalError.
Another limitation is that Pyntch assumes the scope of each namespace is statically defined, i.e. all the names (variables, functions, classes and attributes) are written down in the source code. Therefore a program that define or alter the namespace dynamically during execution cannot be correctly analyzed. Basically, a code has to meet the following conditions:
globals() or locals() function,
nor refering to or altering __dict__ member.
getattr or setattr.
eval, compile or exec functions.
(This section is still way under construction.)
The basic mechanism of Pyntch is based on the idea of "typeflow analysis." This is similar to dataflow analysis, which gives the maximal set of possible data that are stored at each location (either variable or continuation) in a program. First, it constructs a big connected graph that represents the entire Python program. Every expression or statement is converted to a "node", which is an abstraact place where certain type(s) of data is stored or passed. Then it tries to figure out what type of data goes from one node to another.
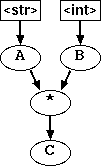
Let us consider a trivial example:
A = 'xyz' B = 2 C = a*b
Given the above statements, Pyntch constructs a graph shown in Fig. 1. A square shaped node is a "leaf" node, which represents a single type of Python object. A round shaped node is a "compound" node, which is a place that one or more types of objects can be potentially stored. Now, the data stored at the top two leaf nodes, which are a string and an integer object respectively, flow down to the lower nodes and each node passes the data according to the arrow. Both objects are "mixed" at the plus sign node, which produces a string object (because in Python multiplying a string and an integer gives a repreated string). Eventually, the object goes into variable c, which is the node at the bottom. This way, you can infer the possible type of each variable.
Now take an example that involves a function:
def foo(x):
return x+1
def bar(y):
return y*2
f = foo
z = f(1)
f = bar
z = f(2)

Copyright (c) 2008-2009 Yusuke Shinyama <yusuke at cs dot nyu dot edu>
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.